-
Cisco Prime Performance Manager User Guide, 1.3
-
Preface
-
Prime Performance Manager Overview
-
Managing Gateways and Units Using the Command Line Interface
-
Managing the Web Interface
-
Integrating Prime Performance Manager with Prime Central
-
Discovering Network Devices
-
Managing Users
-
Managing Reports and Dashboards
-
Managing Devices
-
Managing Network Alarms and Events
-
Managing Thresholds
-
Displaying System Properties, Statuses, Messages, and Logs
-
Managing Gateways and Units
-
Configuring Prime Performance Manager for Firewalls
-
Backing Up and Restoring Prime Performance Manager
-
Prime Performance Manager and IPv6
-
Commands Reference
-
Predefined Thresholds
-
Glossary
-
Index
-
 Feedback
Feedback
Table Of Contents
Displaying Gateway and Unit Information
Displaying Detailed Gateway and Unit Information and Performance
Managing Gateway and Unit Connectivity
Managing Device-to-Unit Assignments
Displaying Device-to-Unit Assignments
Changing a Device-to-Unit Assignment
Creating Unit Protection Groups
Unit Protection Group Failover Scenarios
Managing Gateway High Availability
Managing Local High Availability
Local HA Failovers and Switchovers
Switching the RHCS Cluster Server
Changing the Floating IP Address
Configuring the RHCS Conga Web Interface
Managing Geographical High Availability
Displaying Geographical HA Status
Switch the Primary and Secondary Geographical HA Gateways
Synchronizing the Geographical HA Gateways
Freezing and Unfreezing Geographical HA Gateways
Backing Up and Restoring Geographical HA Gateway Data
Accessing Geographical HA Gateways Using the GUI
Managing Devices in Geographical HA Gateways
Managing Users in Geographical HA Gateways
Managing Reports, Views, and Groups in Geographical HA Gateways
Managing Alarms and Events in Geographical HA Gateways
Managing Thresholds in and Upstream Alarm Hosts in Geographical HA Gateways
Configuring SSL on Geographical HA Gateways and Remote Units
Unit Redundancy Groups and Geographical HA
Managing Geographical and Local High Availability
Managing Gateways and Units
Prime Performance Manager gateway and unit management includes:
•
Displaying gateway and unit information.
•
•
•
The following topics describe gateway and unit management:
•
•
•
•
•
Displaying Gateway and Unit Information
Prime Performance Manager allows you to view information about the gateways and units that are provisioned including details about the gateway and unit servers, alarms, events, and device-to-unit distributions. In addition, you can view more detailed server information including CPU, memory, and disk space utilization, user statistics, and other detailed information.
To display gateway and unit server statistics, from the Performance menu, choose Dashboards, then choose Server Health Dashboards. The following dashboards are displayed:
•
•
•
•
•
•
Note
To display general gateway and unit information, from the System menu, choose Gateway/Units. The System Gateway/Units window displays the gateway and unit properties listed in Table 12-1.
Table 12-1 Gateway and Unit Properties
Internal ID1
Gateway or unit internal ID. Prime Performance Manager assigns the ID for its internal use.
Display Name
Gateway or unit or display name.
Custom Name
Gateway or unit or display name custom name, if created.
IP Address or DNS Hostname
Gateway or unit IP address or DNS name.
Primary SNMP Address
Gateway or unit SNMP IP address.
Redundancy Group1
If the unit belongs to a redundancy group, the redundancy group name. See Creating Unit Protection Groups.
Primary/Redundant1
If the unit belongs to a redundancy group, the unit role in the group, either Primary or Redundant.
Type
Description of the device type, either gateway or unit.
Connection Time
Connection time with the server to a unit or gateway.
In Service
Total time the gateway or unit is in service.
Last Status Change1
Date and time that the status of the gateway or unit last changed.
Status
Current status of the unit or gateway. Possible values are:
•
•
•
•
•
•
•
•
Status Reason
Reason for the current status. For a full list of possible reasons, see the stateReasons.html file, located in the following directory:
/opt/CSCOppm-gw/apache/share/htdocs/eventHelpIf you cannot see all of the status reason, place the cursor over the cell to see the full text in a tooltip.
Out of Sync
If the gateway is installed in a geographical HA configuration, indicates whether the primary gateway database is out of sync to the secondary one.
1 Not displayed by default. To display hidden properties, see Adding and Removing Properties from Property Views.
To display detailed gateway or unit information, select the gateway or unit in the navigation area. Table 12-2 lists the information that is displayed.
Note
Table 12-2 Detailed Gateway and Unit Properties
Reports
Displays gateway or unit reports. These are the same reports you see when choosing Devices from the Network menu, selecting the gateway or unit from the device list and clicking the Reports tab. For more information, see Managing Reports, Dashboards, and Views.
Dashboards
Displays gateway or unit dashboards. These are the same dashboards you see when choosing Devices from the Network menu, selecting the gateway or unit from the device list and clicking the Dashboards tab. For more information, see Managing Reports, Dashboards, and Views.
Details
Provides detailed gateway or unit information. For a description of the detailed gateway and unit information, see Displaying Detailed Gateway and Unit Information and Performance
Event History
Displays the gateway or unit event history. For a description of the event properties, see Displaying Active Alarms and Event History.
Active Alarms
Displays the gateway or unit active alarms. For a description of the alarm properties, see Displaying Active Alarms and Event History.
Report Status
Displays the status of reports generated from the gateway or unit and allows you to enable or disable them. For more information, see Managing Reports, Dashboards, and Views.
Devices for Unit
(Units only)Displays the devices assigned to the selected unit. For a description of device properties, see Displaying Network-Level Device Properties.
Device Distributions for Unit
(Units only)Displays the device distributions for the selected unit. For a description of device properties, see Displaying Device Type Distributions.
Displaying Detailed Gateway and Unit Information and Performance
To display detailed Prime Performance Manager gateway and unit naming, status, and performance information:
Step 1
Step 2
Step 3
The following gateway or unit information is displayed:
•
–
–
–
–
–
–
–
•
–
–
–
–
•
–
–
–
–
Note
•
–
–
–
–
Note
–
–
–
–
–
Managing Gateway and Unit Connectivity
Gateway to unit connectivity requires that the unit hostname be resolvable on the gateway. To ensure gateway-to-unit connectivity is lost due to an unresolved unit hostname, you can perform any of the following actions:
•
/opt/CSCOppm-unit/bin/ppm servername = 1.2.3.4•
•
Managing Device-to-Unit Assignments
Prime Performance Manager allows you to create multiple units, assign them to a gateway and distribute the network devices among them. During device discovery, whether performed from Prime Performance Manager or by importing the Prime Network device inventory, Prime Performance Manager assigns devices to units based upon the device-to-unit mappings that you must create in the Unit Editor administrative tab. You can create these mappings before or after device discovery. If you create the mappings before device discovery, Prime Performance Manager assigns the devices to the units based on the information in the maps. If device-to-unit maps are not present when device discovery is run, Prime Performance Manager assigns all discovered devices to the unit installed with the gateway, if present, or to another unit if a collocated unit is not installed.
Note
The following topics tell you how to create and manage the device-to-unit maps:
•
•
Displaying Device-to-Unit Assignments
If your Prime Performance Manager implementation has only one unit, all devices in your network are assigned to it. If you have allocated devices to multiple units, an easy way to view the device-to-unit assignments is to add the Unit parameter to the Devices table. To do this:
Step 1
Step 2
Step 3
For additional information, see:
•
•
Creating Device-to-Unit Maps
The following procedure tells you how to create a device-to-unit map to distribute devices across multiple units. Before you complete the procedure, you will need the IP addresses or address ranges of all discovered devices, and a plan on how you want to distribute them across the units.
To create the map:
Step 1
Step 2
Step 3
Step 4
•
•
Step 5
The map is added to the Unit Editor table.
Step 6
Step 7
Step 8
•
•
Editing Device-to-Unit Maps
To edit a device-to-unit map, complete the following steps:
Step 1
Step 2
Step 3
•
•
Step 4
Step 5
•
•
Deleting Device-to-Unit Maps
To delete a device-to-unit map:
Step 1
Step 2
Step 3
Step 4
Step 5
•
•
Changing a Device-to-Unit Assignment
If your network has multiple Prime Performance Manager units, you can change the device unit assignment by editing the device-to-unit map. (See Editing Device-to-Unit Maps.) You can also change the device unit assignment by individual device in the Devices window.
To change a device assignment:
Step 1
Step 2
Step 3
Step 4
Note
Step 5
The new device-to-unit assignments will occur immediately.
Creating Unit Protection Groups
Prime Performance Manager protection groups provide protection for units on a 1:1 or N:1 basis, where N = any number of primary units. Prime Performance Manager unit protection groups include the following key points:
•
•
•
•
–
–
–
–
•
•
•
To create a unit redundancy group, use the ppm redundancy command:
ppm redundancygroups [list | detail | create | add | remove | delete | redundant | delay | enable | disable | failover | failback | import | export]
•
ppm redundancygroups listgroupA, Enabled, Number of Units: 2groupB, Enabled, Number of Units: 4•
ppm redundancygroups detail groupAID: 54001Name: groupAEnabledCreated: Wed Sep 21 11:44:36 EDT 2011Create User: localhostLast Modified: Wed Sep 21 11:44:36 EDT 2011Last Modified User: localhostEnabledFail over delay: 60Units: [unit1, Primary,unit2, Redundantunit3, Primaryunit4, Primary•
•
•
Note
•
•
•
•
•
•
•
•
•
Note
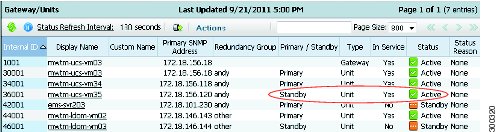
After protection groups are created, you can view them in the Gateway/Units summary list, as shown in Figure 12-1. The Redundancy Group column shows whether the unit belongs to a redundancy group, and if so, the name of the group to which the unit is assigned. The Primary/Redundant column shows the role of the unit in the redundancy group, either primary or redundant, The Status column indicates the unit status, either active or standby.
Figure 12-1 Protection Groups
Figure 12-2 shows a redundant unit that has been switched to active status.
Figure 12-2 Redundant Units in Active Status
Unit Protection Group Failover Scenarios
Table 12-3 describes the unit protection group and failover behavior after common network circumstances occur.
Managing Gateway High Availability
Prime Performance Manager provides both local and geographical high availability. HA installations include:
•
•
•
Prime Performance Manager HA management procedures are provided in the following topics:
•
•
•
Managing Local High Availability
For local HA, Prime Performance Manager uses the Red Hat Cluster Suite (RHCS) provided with the Red Hat Enterprise Linux 5.5 (RHEL 5.5), Red Hat Enterprise Linux 5.7 (RHEL 5.7), Red Hat Enterprise Linux 5.8 (RHEL 5.8) Advanced Program.
The RHCS cluster infrastructure provides the basic functions that allow the Prime Performance Manager gateways to work together as a cluster. RHCS components include:
•
•
•
Note
The Prime Performance Manager local HA utilizes a fencing hardware unit to cut off a gateway server from the shared storage. Fencing ensures data integrity and prevents a split brain scenario, where the gateway servers are disconnected from each other and each assumes the other has failed. If a failure occurs, the cut off can be accomplished by powering off the node with a remote power switch, disabling a switch channel, or revoking a host's SCSI 3 reservations. Figure 12-3 shows the local HA architecture.
Figure 12-3 Local High Availability Architecture
Note
Additional RHCS information can be found at the Red Hat website: http://www.redhat.com/.
Local HA Operations Notes
Before you perform any Prime Performance Manager local HA operation, review the following notes:
•
•
•
•
1.
2.
3.
If you do not freeze RHCS, RHCS will detect the Prime Performance Manager action as a failure and begin the recovery process. This can include restarting and relocating Prime Performance Manager, or disabling the service, which will cause Prime Performance Manager stop working temporally.
Local HA Failovers and Switchovers
After the Prime Performance Manager gateway local HA cluster is deployed, failovers are automatic. If a single service failure occurs, RHCS attempts to restart the service. If the restart fails, the service is relocated and started on the second gateway server.
Human intervention is required only in exceptional cases, such as database corruption or a component failure, and the component is not configured for HA. Manual switchovers are performed using the RHCS web GUI or the CLI clusvcadm utility. After a failed node is repaired, you must perform a manual switchover to revert the cluster to its original configuration.
Note
Two general conditions can trigger Prime Performance Manager local HA failovers:
•
•
–
–
–
During failovers, the gateway does not respond to its attached units, so units cache their requests. After the gateway service is back up, either by restarting the primary gateway successfully or by switching to the secondary gateway, the unit resends cached requests, so no data is lost.
To change the recovery policy after RHCS configuration, use the Red Hat Conga application following procedures in the RHCS documentation. Conga runs on a standalone RHCS server; it is not part of the Prime Performance Manager local HA cluster.
Freezing and Unfreezing RHCS
If you must stop Prime Performance Manager for any reason, you must freeze RHCS so that it stops checking the Prime Performance Manager status. Freezing RHCS places it in maintenance mode. If you stop Prime Performance without freezing RHCS, the cluster will detect that the services are down and attempt to restart it.
To freeze or unfreeze the RHCS cluster service:
Step 1
Step 2
/var/CSCOppm-ha/ppm-ha-binStep 3
./ppmGatewayHA.sh freezeStep 4
./ppmGatewayHA.sh unfreezeAfter unfreeze the service, the RHCS will back to the normal, and begin to check the ppm status periodically.
Switching the RHCS Cluster Server
On occasion, you might need to switch over the RHCS cluster server. To switch the server:
Step 1
Step 2
/var/CSCOppm-ha/ppm-ha-binStep 3
./ppmGatewayHA.sh switchoverThe RHCS service switches from the active to the standby gateway.
Note
Note
Changing the Floating IP Address
Use the following steps if, for any reason, you need to change the floating IP address for the primary and secondary local HA servers:
Step 1
Step 2
ppm stopStep 3
Step 4
Step 5
ppm servername servernameStep 6
ppm gatewayname servernameStep 7
Step 8
RHCS Log Messages
The RHCS log messages provide information about cluster-related issues, such as service failure. Every thirty seconds, RHCS issues status commands to check the Prime Performance Manager, internal database, and other processors. These messages are logged to /var/log/messages and can be viewed by the root user, or from the RHCS web GUI. Sample RHCS log messages are provided below:
Jun 4 07:54:49 crdc-ucs-109 clurgmgrd[7629]: <notice> Starting stopped service service:PPM_GW_HAJun 4 07:54:49 crdc-ucs-109 clurgmgrd: [7629]: <info> mounting /dev/sde1 on /haJun 4 07:54:49 crdc-ucs-109 kernel: kjournald starting. Commit interval 5 secondsJun 4 07:54:49 crdc-ucs-109 kernel: EXT3FS on sde1, internal journalJun 4 07:54:49 crdc-ucs-109 kernel: EXT3-fs: mounted filesystem with ordered data mode.Jun 4 07:54:49 crdc-ucs-109 clurgmgrd: [7629]: <info>quotaopts =Jun 4 07:54:49 crdc-ucs-109 clurgmgrd: [7629]: <info> mounting /dev/sdf1 on /ha_array1Jun 4 07:54:49 crdc-ucs-109 kernel: kjournald starting. Commit interval 5 secondsJun 4 07:54:49 crdc-ucs-109 kernel: EXT3FS on sdf1, internal journalJun 4 07:54:49 crdc-ucs-109 kernel: EXT3-fs: mounted filesystem with ordered data mode.Jun 4 07:54:49 crdc-ucs-109 clurgmgrd: [7629]: <info>quotaopts =Jun 4 07:54:49 crdc-ucs-109 clurgmgrd: [7629]: <info> mounting /dev/sdg1 on /ha_array2Jun 4 07:54:49 crdc-ucs-109 kernel: kjournald starting. Commit interval 5 secondsJun 4 07:54:49 crdc-ucs-109 kernel: EXT3FS on sdg1, internal journalJun 4 07:54:49 crdc-ucs-109 kernel: EXT3-fs: mounted filesystem with ordered data mode.Jun 4 07:54:49 crdc-ucs-109 clurgmgrd: [7629]: <info>quotaopts =Jun 4 07:54:49 crdc-ucs-109 clurgmgrd: [7629]: <info> Adding IPv4 address 10.74.125.114/25 to eth0Jun 4 07:54:51 crdc-ucs-109 avahi-daemon[7490]: Registering new address record for 10.74.125.114 on eth0.Jun 4 07:54:52 crdc-ucs-109 clurgmgrd: [7629]: <info> Executing /ha/CSCOppm-gw/bin/ppmGatewayHealth.sh startJun 4 07:54:52 crdc-ucs-109 logger: start /ha/CSCOppm-gw/bin/sgmServer.sh ....Jun 4 07:54:52 crdc-ucs-109 logger: ppm is not running.Jun 4 07:54:52 crdc-ucs-109 logger: call /ha/CSCOppm-gw/bin/sgmServer.sh start silent 3.Jun 4 07:55:25 crdc-ucs-109 logger: ppm health: everything is OK, return 0Jun 4 07:55:25 crdc-ucs-109 logger: ppm start OK!!!.Jun 4 07:55:25 crdc-ucs-109 clurgmgrd[7629]: <notice> Service service:PPM_GW_HA startedJun 4 07:56:02 crdc-ucs-109 clurgmgrd: [7629]: <info> Executing /ha/CSCOppm-gw/bin/ppmGatewayHealth.sh statusJun 4 07:56:06 crdc-ucs-109 logger: ppm health: everything is OK, return 0Configuring the RHCS Conga Web Interface
The RHCS web interface is configured during installation. Use the information provided in this section only if you decide to change the web interface configuration after installation or if the web interface was not configured during installation.
Installing the RHCS web interface module on a standalone server instead of the dual primary or secondary gateway servers is recommended.
The RHCS luci web interface allows you to configure and manage storage and cluster behavior on remote systems. You will use it to manage the Cisco Prime Performance local HA. Before you begin this procedure, you should have the Red Hat Conga User Manual. It can be obtained at:
http://sources.redhat.com/cluster/conga/doc/user_manual.html
If your fencing device is supported by RHCS but not ipmilan type, that is, you chose the Manual fencing option during the installation; manually configure the device using the Red Hat fencing configuration documentation. This can be obtained at;
http://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux/5/pdf/Configuration_Example_-_Fence_Devices/Red_Hat_Enterprise_Linux-5-Configuration_Example_-_Fence_Devices-en-US.pdf
Note
Note
Step 1
luci_admininitStep 2
# defaults for luci,# web UI fronted for remote cluster and storage managementLUCI_HTTPS_PORT=8084Step 3
serviceluci restartStep 4
https://<node hostname>:<port>Step 5
•
•
•
Step 6
Note
Step 7
https://<cluster node hostname>:<port>From the RHCS web interface you can stop, start, and relocate the services managed by the cluster.
Managing Geographical High Availability
The Prime Performance Manager geographical HA is installed in two different geographical locations, each configured with unique IP addresses. The two gateways work active-active on each site at the same time. The secondary gateway can take over immediately without administrative intervention if the primary site is not available.
This solution supports two kinds of deployment:
•
•
Note
The Prime Performance Manager geographical redundancy gateway HA is based on database and file synchronization:
•
•
Geographical HA management procedures are provided in the following topics:
•
•
•
•
•
•
•
•
•
•
•
•
•
Displaying Geographical HA Status
To display the geographical HA status:
Step 1
Step 2
/opt/CSCOppm-gw/bin/ppm primeha statusPrime Performance Manager provides static configuration and running status information for the primary and secondary gateway. Table 12-4 shows the primary gateway running status.
Table 12-5 shows the secondary gateway running status.
Switch the Primary and Secondary Geographical HA Gateways
On occasion, you might need to manually switch the primary and secondary geographical HA gateways, for example, to perform server maintenance or upgrades, or for other reasons. To manually switch geographical HA gateways:
Step 1
Step 2
•
•
–
–
–
–
–
•
•
Step 3
/opt/CSCOppm-gw/bin/ppm primeha switchAfter the switchover, the following occurs:
•
•
•
•
•
•
•
Configure Geographical HA
You can configure a parameters that affect geographical HA processes. To configure geographical HA:
Step 1
Step 2
/opt/CSCOppm-gw/bin/ppm primeha (peergatewayname | peergatewayrmiport | healthcheckinterval | maxfailnum | synccsv |)Command options include:
•
•
•
•
•
•
•
Synchronizing the Geographical HA Gateways
If the primary and secondary gateways are out of synchronization, as indicated by the primary gateway Out of Sync parameter (see Displaying Geographical HA Status), complete the following steps to synchronize them:
Step 1
Step 2
ppm primeha backupdb {path}Step 3
Step 4
ppm start restoredb {dbpath}Step 5
ppm restart
Freezing and Unfreezing Geographical HA Gateways
If you must stop the primary Prime Performance Manager gateway for any reason, you must freeze the geographical HA gateways to stop the primary and secondary gateway health checking. To freeze the geographical HA gateway;
Step 1
Step 2
Step 3
/opt/CSCOppm-gw/bin/ppm primeha freezeHealth checking will stop on the secondary gateway.
Step 4
/opt/CSCOppm-gw/bin/ppm primeha unfreeze
Backing Up and Restoring Geographical HA Gateway Data
If the geographical gateways get out of synchronization, you will need to back up the primary gateway, copy the files to the secondary gateway and restore the data to it.
To back up and restore geographical HA data:
Step 1
Step 2
/opt/CSCOppm-gw/bin/ppm primeha backupStep 3
/opt/CSCOppm-gw/bin/ppm primeha restore {filename}The gateway system files are restored with specified backup file.
Accessing Geographical HA Gateways Using the GUI
You can view the primary and secondary gateways by choosing Gateways/Units from the System menu. Two gateways are displayed. One has an Active status and one has a Standby status. Any gateway edits can only be applied to the primary (Active) gateway. Changes to the user preference are automatically synchronized to secondary gateway.
Managing Devices in Geographical HA Gateways
Devices can only be imported from Prime Network into the primary HA gateway. Additionally, device discovery can only be run from the primary HA gateway. Device credentials added to the primary gateway are synchronized to secondary gateway. If a switchover or failover occurs, the new primary gateway automatically imports the primary gateway devices.
If Prime Network cross launch capability is implemented, Prime Network cross launches go to the primary HA gateway. After a switchover or failover, the new primary gateway reinstall the cross launch capability.
Any changes to devices credentials are synchronized from the primary to secondary gateway. Device discovery seed files are also synchronized from the primary to secondary gateway.
For information about device discovery, see Chapter 5 "Discovering Network Devices."
Note
Managing Users in Geographical HA Gateways
In a geographical HA environment, users are handled in the following manner:
•
•
For more information, see Chapter 6 "Managing Users and Security."
Managing Reports, Views, and Groups in Geographical HA Gateways
Changes to report settings in the primary gateway are synchronized to the secondary gateway. Report settings cannot be modified in the secondary gateway. Similarly, changes to the primary gateway views are synchronized to the secondary gateway. View modifications can only be performed on the primary gateway. The same principles apply to groups. Group settings cannot be changed on the secondary gateway. However, changes to the primary gateway groups are synchronized to the secondary gateway
Managing Alarms and Events in Geographical HA Gateways
The two HA gateways will display the same alarms and events. Any change to the event, such addition of notes, is synchronized to the secondary gateway. During switchover and failovers, the following events appear:
•
•
If two primary gateways detected, there will also one alarm issued.
If Prime Performance Manager discovers dual primary gateways, the following event is displayed: $LocalPrimaryGateway, $PeerPrimaryGateway.
Managing Thresholds in and Upstream Alarm Hosts in Geographical HA Gateways
Thresholds created on the primary gateway (see "Configuring Thresholds") are synchronized to the secondary gateway. Thresholds cannot changed on the secondary gateway. However, thresholds will operate after a switchover or failover to the secondary gateway. Threshold alarms raised on the primary gateway can be viewed on the secondary gateway.
If the OSS is enabled on the primary gateway (see Configuring Upstream Alarm Hosts and Tuning Event and Alarm Parameters), you can view the configuration results on the secondary gateway. The secondary gateway does not send any traps to its northbound interface unless a switchover or failover occurs.
Configuring SSL on Geographical HA Gateways and Remote Units
The following procedures cover the enabling of SSL on geographical HA gateways and remote units. For additional information, see Enable SSL on a Gateway or Collocated Gateway and Unit.
To enable SSL on the primary gateway:
Step 1
Step 2
Step 3
/opt/CSCOppm-gw/bin/ppm sslenableStep 4
Step 5
To enable SSL on the secondary gateway:
Step 1
Step 2
Step 3
Step 4
Step 5
Step 6
Step 7
Step 8
Step 9
Step 10
Step 11
Enable SSL on remote units:
Step 1
Step 2
Step 3
Step 4
Step 5
Step 6
Step 7
Step 8
Step 9
Step 10
Unit Redundancy Groups and Geographical HA
Any changes to the unit redundancy groups, for example create, add, or delete, are synchronized to the secondary gateway. If a failover occurs in the unit redundancy group or the gateway HA, complete the following steps to stop the servers:
Step 1
Step 2
Step 3
Wait until all units are completely shut down.
Step 4
Step 5
Managing Geographical and Local High Availability
If Prime Performance Manager gateway HA is installed with a local HA, the two local gateways are combined as the one active gateway for geographical HA, and the remote geographical HA gateway is the standby. To manage the local HA gateways, follow the procedures in Managing Local High Availability. To manage geographical HA, follow procedures in Managing Geographical High Availability.
Manual Disaster Recovery
If a disaster occurs and primary gateway become inoperable, the secondary gateway becomes active and Prime Performance Manager continues to function, with the following exceptions:
•
•
•
•
After the primary gateway is restored, complete the following steps to bring it back online:
Step 1
Step 2
Step 3