The ability of a high-performance cluster (HPC) to positively affect application performance is one of the most important factors to consider in selecting a switching fabric type and interconnect. Though the characteristics of an application affect performance results, you also should consider node configuration, interconnect and switching fabric type and configuration, protocol offloading technology, storage, and file system type
This document presents a comparative analysis of the performance of LS-DYNA, a finite element analysis application, using two interconnect and fabric technologies: Gigabit Ethernet and Cisco® Double Data Rate (DDR) InfiniBand.
HPC Interconnects
Today's computing environments use several different interconnects and technologies for interprocess communication (IPC) traffic. The interconnects and fabrics used in the LS-DYNA application performance and scalability testing discussed here are Gigabit Ethernet and a new technology called Cisco DDR InfiniBand.
Gigabit Ethernet is an established standard technology that is well understood and popular in HPC environments. Cisco DDR InfiniBand is a new advancement that is based on the well-established standard single-data-rate (SDR) technology. DDR aggregates four 4-Gbps links, resulting in a 16-Gbps physical connection.
Application Performance
Cluster performance is judged by the total run time, or wall-clock time, of the application. The shorter the wall-clock time, the more application processing can be performed, and the lower the cost per application process. The main areas affecting application performance are message latency, CPU use and contention, and I/O latency for data set access.
Test Methodology
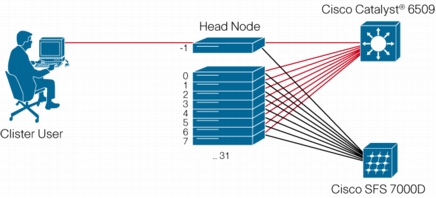
This document focuses on actual application performance metrics by measuring the performance of an application as the number of nodes in the cluster changes. For this test, the LS-DYNA crash simulation application was used. This document contains real application performance data for clusters scaling to 64 CPUs, comparing the widely used Gigabit Ethernet and Cisco DDR InfiniBand interconnects. Figure 1 shows the cluster setup used in this test.
Figure 1. Cluster System Setup with Two Fabric
Each test case was run serially as a single process on a single processor and then in parallel with increasing numbers of processors. Note that each server node in the cluster has two processors in a symmetric multiprocessing (SMP) configuration. Jobs were run with a 1:1 process-to-processor ratio. Each test case was run three times, and the results were averaged to improve accuracy.
LS-DYNA
LS-DYNA (http://www.lstc.com/) is a recognized commercial finite element analysis application that is used for several types of analysis. Some of many common uses include automobile crash analysis, building collapse analysis, material formation and failure analysis, and heat transfer analysis.
For the analysis in this test, two recognized vehicle crash benchmarks were used: the Three-Car Crash Test simulation and the Neon-Refined Crash Test simulation. The latter is specific to the Dodge Neon automobile.
Information on the use of LS-DYNA by various organizations can be found at http://www.dynalook.com/.
Testing Setup
Hardware for Gigabit Ethernet Tests
• Servers: Dual-core and dual-socket Intel 5160 processor (3.0 GHz) with 8 GB RAM
When analyzing performance data for applications such as LS-DYNA, the less the total time to job completion, the better.
Tables 1 and 2 show that Cisco InfiniBand DDR scales much better in both the Three-Car Crash Test simulation and the Neon Refined Test simulation.
The total time required for Ethernet jobs increases as the number of processors increases. Job slowdown occurs as the number of CPUs increases likely because IPC overwhelms the computation in the processing. These performance tests used MPI over TCP over Gigabit Ethernet.
In the InfiniBand DDR tests, the total time required for jobs is less than for Gigabit Ethernet, and it scales even better as the number of processors increases. These performance tests used MPI over the InfiniBand verbs interface (an optimized communication interface for InfiniBand).