|
Not reporting all interface transitions from the physical layer up to the routing protocol. This is called debouncing the
interface; most interface types wait some number of milliseconds before reporting a change in the interface state. |
|
Slow neighbor down timers. For instance, the amount of time a router waits without hearing from a given neighbor before
declaring that a neighbor has failed is generally on the order of tens of seconds in most routing protocols. The dead timer
does not impact downneighbor detection on point-to-point links, because when the interface fails, the neighbor is assumed to be
down, but there are other "slow-down" timers here, as well. |
|
Slow down the distribution of information about topology changes. |
|
Slow down the time within which the routing protocol reacts to information about topology changes. |
|
In IS-IS, a timer regulates how often an intermediate system (router) may originate new routing information, and how often
a router may run the shortest path first (SPF) algorithm used to calculate the best paths through the network. |
|
In OSPF, similar timers regulate the rate at which topology information can be transmitted, and how often the shorter path
first algorithm may be run. |
|
In EIGRP, the simple rule: "no route may be advertised until it is installed in the local routing table" dampens the speed
at which routing information is propagated through the network, and routing information is also paced when being transmitted
through the network based on the bandwidth between two routers. |
|
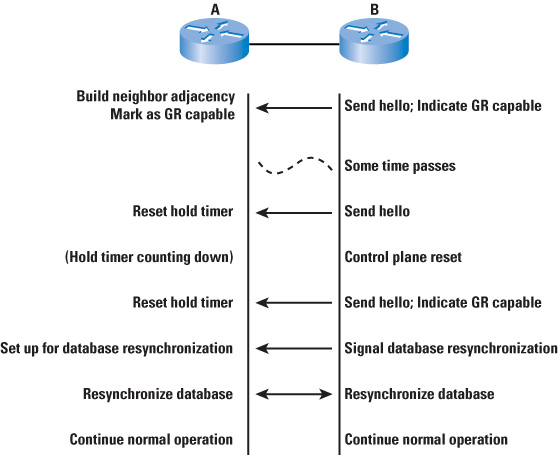
The normal hold times are acceptable, within this network environment, for reporting a network event or topology change. In
other words, if a router's control plane fails, the event wouldn't be reported until the routing protocol's default hold or
dead timers expire, whether or not GR is configured. |
|
The control plane on the router can reload and begin processing data within the hold or dead time of the routing
protocol. |
|
EIGRP running over a point-to-point link sends one Hello every 5 seconds, and declares a neighbor down if no Hellos are
heard for 15 seconds. |
|
EIGRP running over a lower-speed point-to-multipoint link sends one Hello every 60 seconds, and declares a neighbor down if
no Hellos are received in 180 seconds. |
|
OSPF normally sends a Hello every 10 seconds, and declares a neighbor down if no Hellos are heard for 40 seconds. |
|
Frame Relay Local Management Interface (LMI) messages, the equivalent of a Hello, are transmitted every 10
seconds. If an LMI is not received in 30 seconds, the circuit is assumed to have failed. |
|
High-Level Data Link Control (HDLC) keepalive messages are transmitted every 10 seconds. If a keepalive message is
not received within 30 seconds, the circuit is assumed to have failed. |
|
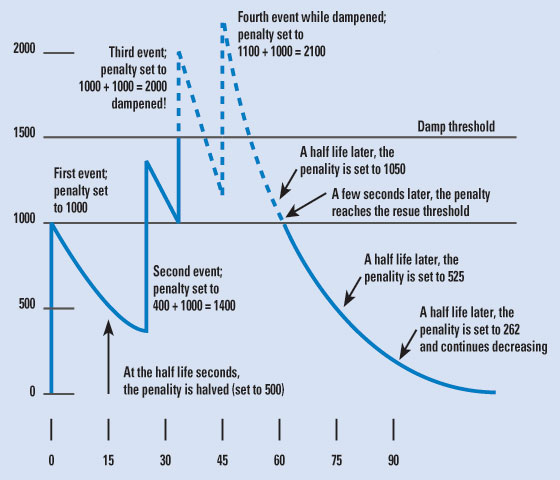
Border Gateway Protocol (BGP) route flap dampening |
|
Interface dampening |
|
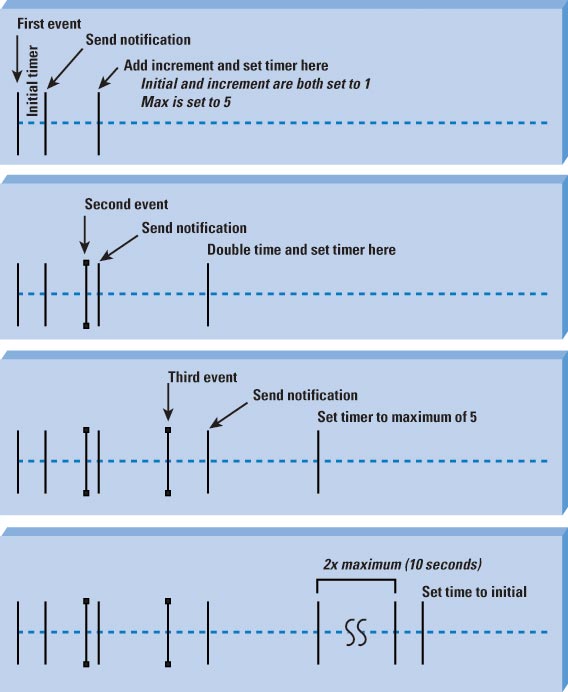
The ability to exponentially back off the amount of time between a change in the network topology being detected and the
transmission of a link state packet being transmitted to report the change; exponential backoff has been applied to the link
state generation timer. |
|
The ability to exponentially back off the amount of time between receiving a link state packet reporting a change in the
network topology, and running SPF to recalculate the path to each reachable destination in the network; exponential backoff has
been applied to the SPF timer. |
|
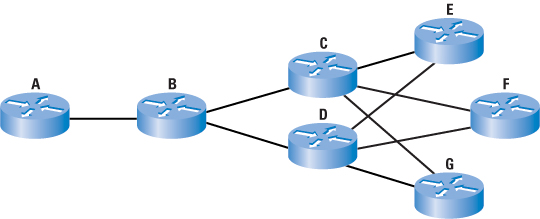
Fast reaction to node or link failure, to route around the failure. We use Layer 2 techniques and Fast Hellos to
quickly determine when an adjacent node, or a link to that node, has failed. |
|
Slow reaction to node of link failure, combined with routing through the failure. We rely on moderate speed reactions to
node failures to allow resynchronization of routing data while forwarding of traffic continues. |
|
Fast recalculation of the best path when a topology change has been reported. |
|
If there is a fast, online backup available to a node or a link, it probably makes more sense to route around any problems
that occur as rapidly as possible. |
|
If any existing backup is going to take a good deal of time to bring online, or there is no backup path (such as a single
homed remote office, or a remote office with dial backup), it probably makes more sense to route through any problems. |